
Firma Panasonic Holdings Co. Ltd. opracowała sztuczną inteligencję do rozpoznawania obrazów z nowym algorytmem klasyfikacji, który może obsługiwać multimodalny charakter danych pochodzących z obiektu i warunków fotografowania. Eksperymenty wykazały, że dokładność rozpoznawania przekracza dokładność konwencjonalnych metod.
Sztuczna inteligencja rozpoznająca obraz rozpoznaje obiekty, klasyfikując je do kategorii na podstawie ich wyglądu. Istnieje jednak wiele przypadków, w których nawet obiekty należące do tej samej kategorii, takie jak „pociąg” lub „pies”, są klasyfikowane w podkategoriach, takich jak „typ pociągu” lub „rasa psa”, mających bardzo różny wygląd. Co więcej, istnieje wiele przypadków, w których ten sam obiekt może wyglądać inaczej z powodu różnic w warunkach fotografowania, takich jak orientacja, pogoda, oświetlenie lub tło. Ważne jest, aby zastanowić się, jak najlepiej radzić sobie z taką różnorodnością wyglądu.
Aby poprawić dokładność rozpoznawania obrazów, do tej pory przeprowadzono badania mające na celu osiągnięcie niezawodnego rozpoznawania obrazów, na które nie ma wpływu różnorodność, a algorytmy klasyfikacji zostały opracowane w celu znalezienia podobieństw w podkategoriach i cech wspólnych dla obiektów w danej kategorii.
Ponieważ sztuczna inteligencja jest nadal wdrażana w różnych środowiskach i przetwarzana jest duża liczba różnorodnych obrazów, widoczne stały się ograniczenia podejścia polegającego na „znajdowaniu wspólnych cech”. W szczególności, gdy istnieją podkategorie o różnych tendencjach wyglądu w ramach tej samej kategorii (rozkład multimodalny), sztuczna inteligencja często ma trudności z pomyślnym rozpoznaniem takich obiektów jako należących do tej samej kategorii, co skutkuje spadkiem dokładności rozpoznawania.
Dlatego Panasonic skupił się na wykorzystaniu różnic w wyglądzie i opracował nowy algorytm klasyfikacji, który rejestruje różnorodność obrazów za pomocą dwuwymiarowej macierzy ortonormalnej. Korzystając z wzorcowego zestawu danych*1, wykazaliśmy, że możliwe jest przeprowadzenie bardzo dokładnej klasyfikacji obrazów nawet na danych o rozkładzie multimodalnym, co jest trudne dla sztucznej inteligencji.
Technologia ta jest wynikiem badań REAL-AI*2, programu szkolenia ekspertów AI Grupy Panasonic, i została przyjęta na IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2024), najważniejszą konferencję w dziedzinie wizji komputerowej. Prezentacja zostanie przedstawiona na konferencji plenarnej na Hawajach w USA, która odbędzie się w dniach od 4 do 8 stycznia 2024 roku.
Panasonic HD będzie promować badania i rozwój technologii sztucznej inteligencji, która przyspiesza jej wdrażanie w społeczeństwie, jednocześnie koncentrując się na szkoleniu najlepszych ekspertów w tej dziedzinie.
Omówienie działania nowego AI
Zastosowania technologii rozpoznawania obrazów rosną, a technologia ta rozszerza się na sytuacje, w których wcześniej nie była używana. Ponieważ jej zastosowania wykraczają poza obszary, w których była łatwiejsza do zastosowania, istnieje potrzeba radzenia sobie z obiektami w tej samej kategorii, które mogą pojawiać się na różne sposoby, z czym konwencjonalna sztuczna inteligencja ma trudności.
W konwencjonalnych ramach głębokiego uczenia model sztucznej inteligencji zasadniczo uczy się, że rzeczy, które wyglądają podobnie, należą do tych samych kategorii. Jednak w ostatnich latach, w celu poprawy wydajności klasyfikacji, powszechne stało się znaczne zwiększenie liczby danych i różnic w wyglądzie podczas procesu uczenia się. Umożliwia to określenie, że dane obiekty należą do tej samej kategorii, nawet jeśli obiekty wyglądają zupełnie inaczej w zależności od czynników takich jak orientacja fotografowania, oświetlenie i tło. Z tego powodu skupiono się na tym, jak sprawić, by sztuczna inteligencja skutecznie uczyła się podstawowych cech wspólnych dla obiektów docelowych bez rozpraszania się różnorodnością wyglądu zawartą w dużych ilościach danych.
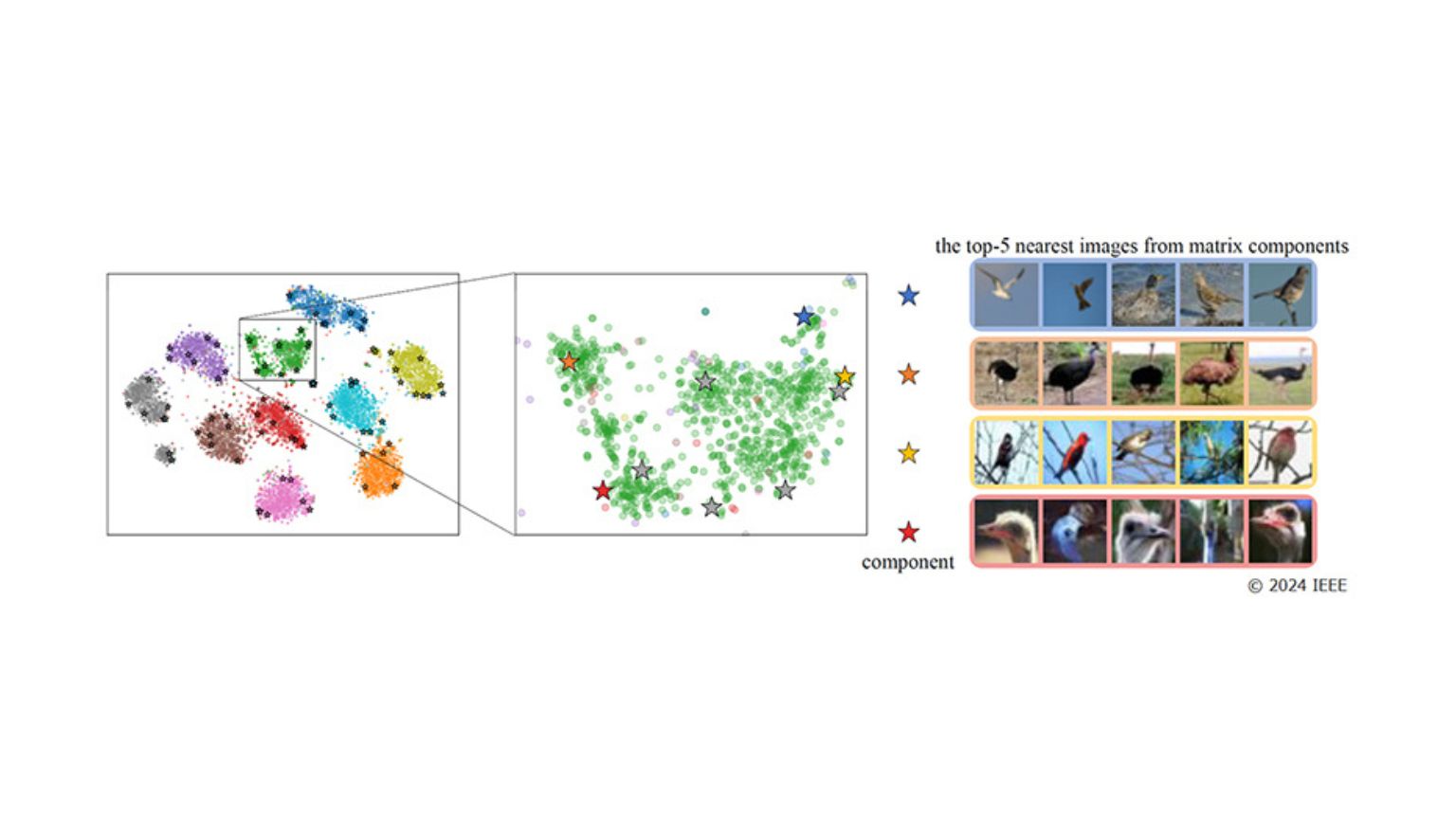
Rozkład wyglądów w ramach kategorii nie jest w rzeczywistości jednolity. W ramach tej samej kategorii istnieje wiele podkategorii z wieloma różnymi trendami w wyglądzie (rozkład multimodalny). Na przykład w kategorii „Ptaki” pokazanej na rysunku 1 istnieją grupy obrazów tego samego ptaka o różnych tendencjach, takich jak „ptaki latające na niebie”, „ptaki na łące”, „ptaki siedzące na drzewach” i „ptasie głowy”. Każdy z tych obrazów zawiera bogate informacje o obiekcie. Jeśli skupimy się na podstawowych cechach, w końcu odrzucimy różnorodne informacje, które zawierają obrazy.
Dlatego opracowaliśmy algorytm, który aktywnie wykorzystuje informacje o różnych sposobach pojawiania się obiektów, aby poprawić zdolność sztucznej inteligencji do rozpoznawania obrazów o dystrybucji multimodalnej, co jest trudne dla sztucznej inteligencji. Aby w sposób ciągły przechwytywać rozkład cech, rozszerzyliśmy wektor wagowy modelu klasyfikacji, który tradycyjnie był tylko wektorem jednowymiarowym, do dwuwymiarowej macierzy ortonormalnej. Pozwala to każdemu elementowi macierzy wag reprezentować odmianę obrazu (różne kolory tła, orientacja obiektu itp.).










